
The world is witnessing a technological revolution, and OpenAI is at the forefront of this change. One of its most exciting innovations is ChatGPT — that utilizes natural language processing to create more engaging and intuitive user experiences. The integration of OpenAI APIs with IoT devices has opened up a world of possibilities.

In this article, we will explore the potential of ChatGPT with ESP-BOX, a powerful combination that can take IoT devices to the next level.
ESP-BOX#
The ESP-BOX is a new generation AIoT development platform that includes the ESP32-S3-BOX and ESP32-S3-BOX-Lite development boards. These boards are based on the ESP32-S3 Wi-Fi + Bluetooth 5 (LE) SoC and provide a flexible and customizable solution for developing AIoT applications that integrate with various sensors, controllers, and gateways.

The ESP-BOX is packed with a wide range of features that make it an ideal AIoT development platform. Let’s take a closer look at some of the key features
Case Study#
Developing a Voice-Controlled Chatbot using ESP-BOX and OpenAI APIs.
Description#
This case study outlines the development process for a voice-controlled chatbot that utilizes the combination of ESP-BOX and OpenAI API. The system is capable of receiving speech commands from users, displaying them on the screen, and processing them through the OpenAI APIs to generate a response. The response is then displayed on the screen and played through the ESP-BOX. The step-by-step workflow provides a detailed explanation of how to integrate these technologies to create an efficient and effective voice-controlled chatbot.
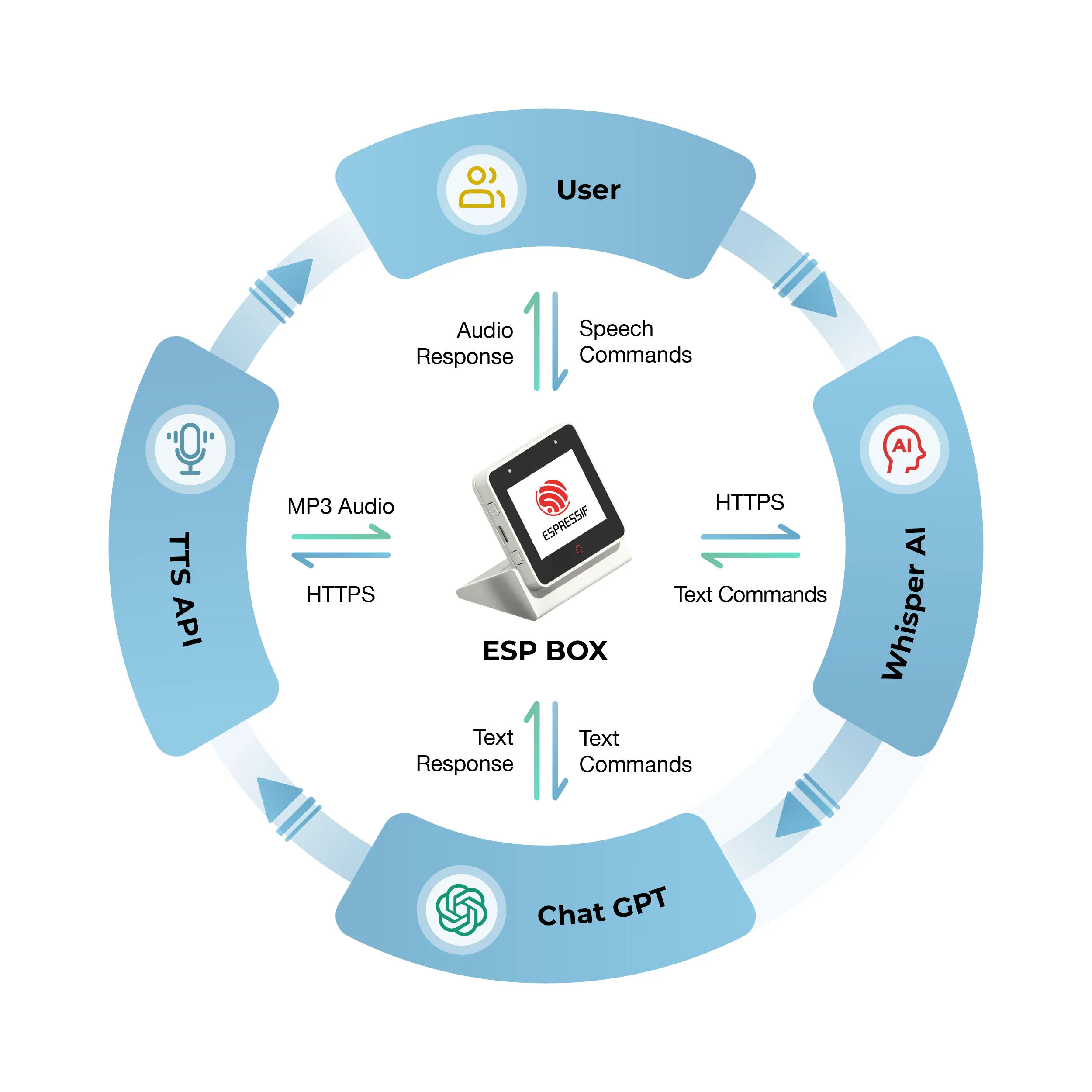
Environment Setup#
Setting up a suitable environment and installing the correct version is critical to avoid errors.
- ESP-IDF
In this demonstration, we’ll be utilizing ESP-IDF version 5.0 (master branch). If you need guidance on how to set up ESP-IDF, please refer to the official IDF Programming guide for detailed information.
**As of writing of this blog, the current IDF commit head is df9310ada2.*
- ChatGPT API
To utilize ChatGPT, a powerful language model based on the GPT-3.5 architecture, you must first obtain a secure API key. This can be achieved by creating an account on the OpenAI platform and obtaining tokens through creation or purchase. With an API key, you gain access to a wide range of features and capabilities that can be customized to meet your specific needs, such as natural language processing and generation, text completion, and conversation modeling. Follow the official API reference link.
**Maintaining the confidentiality and security of the API key is crucial to prevent unauthorized access to the user’s account and data.*
Adding Offline Speech Recognition#
Espressif Systems, has as developed an innovative speech recognition framework called ESP-SR. This framework is designed to enable devices to recognize spoken words and phrases without relying on external cloud-based services, making it an ideal solution for offline speech recognition applications.
ESP-SR framework consists of various modules, including the Audio Front-end (AFE), Wake Word Engine (WakeNet), Speech Command Word Recognition (MultiNet), and Speech Synthesis (which currently only supports the Chinese language). Follow the official Documentation for more information.
Integrating OpenAI API#
The OpenAI API provides numerous functions that developers can leverage to enhance their applications. In our project, we utilized the Audio-to-Text and Completion APIs and implemented them using C-language code based on ESP-IDF. The following section provides a brief overview of the code we employed.
- Audio to Text
To extract text from audio, we utilize HTTPS and OpenAI Audio API. The following code is used for this task.
esp_err_t create_whisper_request_from_record(uint8_t *audio, int audio_len)
{
// Set the authorization headers
char url[128] = "https://api.openai.com/v1/audio/transcriptions";
char headers[256];
snprintf(headers, sizeof(headers), "Bearer %s", OPENAI_API_KEY);
// Configure the HTTP client
esp_http_client_config_t config = {
.url = url,
.method = HTTP_METHOD_POST,
.event_handler = response_handler,
.buffer_size = MAX_HTTP_RECV_BUFFER,
.timeout_ms = 60000,
.crt_bundle_attach = esp_crt_bundle_attach,
};
// Initialize the HTTP client
esp_http_client_handle_t client = esp_http_client_init(&config);
// Set the headers
esp_http_client_set_header(client, "Authorization", headers);
// Set the content type and the boundary string
char boundary[] = "boundary1234567890";
char content_type[64];
snprintf(content_type, sizeof(content_type), "multipart/form-data; boundary=%s", boundary);
esp_http_client_set_header(client, "Content-Type", content_type);
// Set the file data and size
char *file_data = NULL;
size_t file_size;
file_data = (char *)audio;
file_size = audio_len;
// Build the multipart/form-data request
char *form_data = (char *)malloc(MAX_HTTP_RECV_BUFFER);
assert(form_data);
ESP_LOGI(TAG, "Size of form_data buffer: %zu bytes", sizeof(*form_data) * MAX_HTTP_RECV_BUFFER);
int form_data_len = 0;
form_data_len += snprintf(form_data + form_data_len, MAX_HTTP_RECV_BUFFER - form_data_len,
"--%s\r\n"
"Content-Disposition: form-data; name=\"file\"; filename=\"%s\"\r\n"
"Content-Type: application/octet-stream\r\n"
"\r\n", boundary, get_file_format(file_type));
ESP_LOGI(TAG, "form_data_len %d", form_data_len);
ESP_LOGI(TAG, "form_data %s\n", form_data);
// Append the audio file contents
memcpy(form_data + form_data_len, file_data, file_size);
form_data_len += file_size;
ESP_LOGI(TAG, "Size of form_data: %zu", form_data_len);
// Append the rest of the form-data
form_data_len += snprintf(form_data + form_data_len, MAX_HTTP_RECV_BUFFER - form_data_len,
"\r\n"
"--%s\r\n"
"Content-Disposition: form-data; name=\"model\"\r\n"
"\r\n"
"whisper-1\r\n"
"--%s--\r\n", boundary, boundary);
// Set the headers and post field
esp_http_client_set_post_field(client, form_data, form_data_len);
// Send the request
esp_err_t err = esp_http_client_perform(client);
if (err != ESP_OK) {
ESP_LOGW(TAG, "HTTP POST request failed: %s\n", esp_err_to_name(err));
}
// Clean up client
esp_http_client_cleanup(client);
// Return error code
return err;
}
This code is a function named “whisper_from_record”, which takes in a pointer to a buffer containing the audio data and an integer “*audio_len *” that represents the length of the audio data. This function sends a POST request to the OpenAI API endpoint to transcribe the given audio data.
The function starts by initializing the URL of the OpenAI API and setting the authorization headers with the bearer token “OPENAI_API_KEY”. Then, an HTTP client is configured and initialized with the provided configuration, including the URL, HTTP method, event handler, buffer size, timeout, and SSL certificate.
After that, the content type and the boundary string for the multipart form-data request are set as headers to the HTTP client. The file data and its size are also set, and a multipart/form-data request is built. The “form_data” buffer is allocated with a malloc() function, and the necessary information is added to it. This includes the filename and Content-Type of the audio file, the file contents, and the name of the model that will be used for transcription.
Once the “*form_data *”is built, it is set as the post field in the HTTP client, and the client sends the POST request to the OpenAI API endpoint. If there is an error during the request, the function logs an error message. Finally, the HTTP client is cleaned up, and the resources allocated for form_data are freed.
The function returns an esp_err_t error code, which indicates whether the HTTP request was successful or not.
- Chat Completion
The OpenAI Chat Completion API is utilized to send HTTPS requests for chat completion. This process involves utilizing the create_chatgpt_request function, which takes in a content parameter representing the input text to the GPT-3.5 model.
esp_err_t create_chatgpt_request(const char *content)
{
char url[128] = "https://api.openai.com/v1/chat/completions";
char model[16] = "gpt-3.5-turbo";
char headers[256];
snprintf(headers, sizeof(headers), "Bearer %s", OPENAI_API_KEY);
esp_http_client_config_t config = {
.url = url,
.method = HTTP_METHOD_POST,
.event_handler = response_handler,
.buffer_size = MAX_HTTP_RECV_BUFFER,
.timeout_ms = 30000,
.crt_bundle_attach = esp_crt_bundle_attach,
};
// Set the headers
esp_http_client_handle_t client = esp_http_client_init(&config);
esp_http_client_set_header(client, "Content-Type", "application/json");
esp_http_client_set_header(client, "Authorization", headers);
// Create JSON payload with model, max tokens, and content
snprintf(json_payload, sizeof(json_payload), json_fmt, model, MAX_RESPONSE_TOKEN, content);
esp_http_client_set_post_field(client, json_payload, strlen(json_payload));
// Send the request
esp_err_t err = esp_http_client_perform(client);
if (err != ESP_OK) {
ESP_LOGW(TAG, "HTTP POST request failed: %s\n", esp_err_to_name(err));
}
// Clean up client
esp_http_client_cleanup(client);
// Return error code
return err;
}
The function first sets up the URL, model, and headers needed for the HTTP POST request, and then creates a JSON payload with the model, max tokens, and content.
Next, the function sets the headers for the HTTP request and sets the JSON payload as the post field for the request.
The HTTP POST request is then sent using “esp_http_client_perform()”, and if the request fails, an error message is logged.
Finally, the HTTP client is cleaned up and the error code is returned.
- Handling Response
Callback function “*response_handler *”that is used by the ESP-IDF HTTP client library to handle events that occur during an HTTP request/response exchange.
esp_err_t response_handler(esp_http_client_event_t *evt)
{
static char *data = NULL; // Initialize data to NULL
static int data_len = 0; // Initialize data to NULL
switch (evt->event_id) {
case HTTP_EVENT_ERROR:
ESP_LOGI(TAG, "HTTP_EVENT_ERROR");
break;
case HTTP_EVENT_ON_CONNECTED:
ESP_LOGI(TAG, "HTTP_EVENT_ON_CONNECTED");
break;
case HTTP_EVENT_HEADER_SENT:
ESP_LOGI(TAG, "HTTP_EVENT_HEADER_SENT");
break;
case HTTP_EVENT_ON_HEADER:
if (evt->data_len) {
ESP_LOGI(TAG, "HTTP_EVENT_ON_HEADER");
ESP_LOGI(TAG, "%.*s", evt->data_len, (char *)evt->data);
}
break;
case HTTP_EVENT_ON_DATA:
ESP_LOGI(TAG, "HTTP_EVENT_ON_DATA (%d +)%d\n", data_len, evt->data_len);
ESP_LOGI(TAG, "Raw Response: data length: (%d +)%d: %.*s\n", data_len, evt->data_len, evt->data_len, (char *)evt->data);
// Allocate memory for the incoming data
data = heap_caps_realloc(data, data_len + evt->data_len + 1, MALLOC_CAP_SPIRAM | MALLOC_CAP_8BIT);
if (data == NULL) {
ESP_LOGE(TAG, "data realloc failed");
free(data);
data = NULL;
break;
}
memcpy(data + data_len, (char *)evt->data, evt->data_len);
data_len += evt->data_len;
data[data_len] = '\0';
break;
case HTTP_EVENT_ON_FINISH:
ESP_LOGI(TAG, "HTTP_EVENT_ON_FINISH");
if (data != NULL) {
// Process the raw data
parsing_data(data, strlen(data));
// Free memory
free(data);
data = NULL;
data_len = 0;
}
break;
case HTTP_EVENT_DISCONNECTED:
ESP_LOGI(TAG, "HTTP_EVENT_DISCONNECTED");
break;
default:
break;
}
return ESP_OK;
}
In case of “HTTP_EVENT_ON_DATA”, the function allocates memory for the incoming data, copies the data into the buffer and increments the “*data_len *”variable accordingly. This is done to accumulate the response data.
In case of “HTTP_EVENT_ON_FINISH”, the function prints a message indicating that the HTTP exchange has finished, and then calls the “*parsing_data *”function to process the accumulated/raw data. It then frees the memory and resets the data and “*data_len *”variables to zero. It then frees the allocated memory and resets the buffer and its length to zero.
Finally, the function returns “*ESP_OK *”indicating that the operation was successful.
- Parsing Raw Data
The JSON parser component is utilized to parse the raw response obtained from ChatGPT API and Whisper AI API over HTTPS. To perform this task, a function is used, which employs the parser component. Further details about this tool can be found on GitHub.
void parse_response (const char *data, int len)
{
jparse_ctx_t jctx;
int ret = json_parse_start(&jctx, data, len);
if (ret != OS_SUCCESS) {
ESP_LOGE(TAG, "Parser failed");
return;
}
printf("\n");
int num_choices;
/* Parsing Chat GPT response*/
if (json_obj_get_array(&jctx, "choices", &num_choices) == OS_SUCCESS) {
for (int i = 0; i < num_choices; i++) {
if (json_arr_get_object(&jctx, i) == OS_SUCCESS && json_obj_get_object(&jctx, "message") == OS_SUCCESS &&
json_obj_get_string(&jctx, "content", message_content, sizeof(message_content)) == OS_SUCCESS) {
ESP_LOGI(TAG, "ChatGPT message_content: %s\n", message_content);
}
json_arr_leave_object(&jctx);
}
json_obj_leave_array(&jctx);
}
/* Parsing Whisper AI response*/
else if (json_obj_get_string(&jctx, "text", message_content, sizeof(message_content)) == OS_SUCCESS) {
ESP_LOGI(TAG, "Whisper message_content: %s\n", message_content);
} else if (json_obj_get_object(&jctx, "error") == OS_SUCCESS) {
if (json_obj_get_string(&jctx, "type", message_content, sizeof(message_content)) == OS_SUCCESS) {
ESP_LOGE(TAG, "API returns an error: %s", message_content);
}
}
}
Integrating TTS API#
At the moment, OpenAI doesn’t offer public access to their Text-to-Speech (TTS) API. However, there are various other TTS APIs available, including Voicerss, TTSmaker, and TalkingGenie. These APIs can generate speech from text input, and you can find more information about them on their respective websites.
For the purposes of this tutorial, we will be using the TalkingGenie API, which is one of the best options available for generating high-quality, natural-sounding speech both in English and Chinese. One of the unique features of TalkingGenie is its ability to translate mixed language text, such as Chinese and English, into speech seamlessly. This can be a valuable tool for creating content that appeals to a global audience. The following code sends a text response generated by ChatGPT to the TalkingGenie API using HTTPS, and then plays the resulting speech through an ESP-BOX.
esp_err_t text_to_speech_request(const char *message, AUDIO_CODECS_FORMAT code_format)
{
int j = 0;
size_t message_len = strlen(message);
char *encoded_message;
char *language_format_str, *voice_format_str, *codec_format_str;
// Encode the message for URL transmission
encoded_message = heap_caps_malloc((3 * message_len + 1), MALLOC_CAP_SPIRAM | MALLOC_CAP_8BIT);
url_encode(message, encoded_message);
// Determine the audio codec format
if (AUDIO_CODECS_MP3 == code_format) {
codec_format_str = "MP3";
} else {
codec_format_str = "WAV";
}
// Determine the required size of the URL bu
int url_size = snprintf(NULL, 0, "https://dds.dui.ai/runtime/v1/synthesize?voiceId=%s&text=%s&speed=1&volume=%d&audiotype=%s", \
VOICE_ID, \
encoded_message, \
VOLUME, \
codec_format_str);
// Allocate memory for the URL buffer
char *url = heap_caps_malloc((url_size + 1), MALLOC_CAP_SPIRAM | MALLOC_CAP_8BIT);
if (url == NULL) {
ESP_LOGE(TAG, "Failed to allocate memory for URL");
return ESP_ERR_NO_MEM;
}
// Format the URL string
snprintf(url, url_size + 1, "https://dds.dui.ai/runtime/v1/synthesize?voiceId=%s&text=%s&speed=1&volume=%d&audiotype=%s", \
VOICE_ID, \
encoded_message, \
VOLUME, \
codec_format_str);
// Configure the HTTP client
esp_http_client_config_t config = {
.url = url,
.method = HTTP_METHOD_GET,
.event_handler = http_event_handler,
.buffer_size = MAX_FILE_SIZE,
.buffer_size_tx = 4000,
.timeout_ms = 30000,
.crt_bundle_attach = esp_crt_bundle_attach,
};
// Initialize and perform the HTTP request
esp_http_client_handle_t client = esp_http_client_init(&config);
esp_err_t err = esp_http_client_perform(client);
if (err != ESP_OK) {
ESP_LOGE(TAG, "HTTP GET request failed: %s", esp_err_to_name(err));
}
// Free allocated memory and clean up the HT
heap_caps_free(url);
heap_caps_free(encoded_message);
esp_http_client_cleanup(client);
// Return the result of the function call
return err;
}
The function “*text_to_speech *” takes a message string and an “AUDIO_CODECS_FORMAT” parameter as input. The message string is the text that will be synthesized into speech, while the “*AUDIO_CODECS_FORMAT *” parameter specifies whether the speech should be encoded in MP3 or WAV format.
The function first encodes the message string using “url_encode” function that replace some non-valid characters to its ASCII code, and then converts that code to a two-digit hexadecimal representation. Next allocates memory for the resulting encoded string. It then checks the “AUDIO_CODECS_FORMAT” parameter and sets the appropriate codec format string to be used in the “url”.
Next, the function determines the size of the “url” buffer needed to make a GET request to the TalkingGenie API, and allocates memory for the “url” buffer accordingly. It then formats the “url” string with the appropriate parameters, including the voiceId (which specifies the voice to be used), the encoded text, the speed and volume of the speech, and the audiotype (either “MP3” or “WAV”).
The function then sets up an “esp_http_client_config_t” struct with the “url” and other configuration parameters, initializes an esp_http_client_handle_t with the struct, and performs a GET request to the TalkingGenie API using “esp_http_client_perform”. If the request is successful, the function returns ESP_OK, otherwise it returns an error code.
Finally, the function frees the memory allocated for the “url” buffer and the encoded message, cleans up the “esp_http_client_handle_t”, and returns the error code.
- Handling TTS Response
In the similar fashion Callback function “http_event_handler” is defined to handle events that occur during an HTTP request/response exchange.
static esp_err_t http_event_handler(esp_http_client_event_t *evt)
{
switch (evt->event_id) {
// Handle errors that occur during the HTTP request
case HTTP_EVENT_ERROR:
ESP_LOGE(TAG, "HTTP_EVENT_ERROR");
break;
// Handle when the HTTP client is connected
case HTTP_EVENT_ON_CONNECTED:
ESP_LOGI(TAG, "HTTP_EVENT_ON_CONNECTED");
break;
// Handle when the header of the HTTP request is sent
case HTTP_EVENT_HEADER_SENT:
ESP_LOGI(TAG, "HTTP_EVENT_HEADER_SENT");
break;
// Handle when the header of the HTTP response is received
case HTTP_EVENT_ON_HEADER:
ESP_LOGI(TAG, "HTTP_EVENT_ON_HEADER");
file_total_len = 0;
break;
// Handle when data is received in the HTTP response
case HTTP_EVENT_ON_DATA:
ESP_LOGI(TAG, "HTTP_EVENT_ON_DATA, len=%d", evt->data_len);
if ((file_total_len + evt->data_len) < MAX_FILE_SIZE) {
memcpy(record_audio_buffer + file_total_len, (char *)evt->data, evt->data_len);
file_total_len += evt->data_len;
}
break;
// Handle when the HTTP request finishes
case HTTP_EVENT_ON_FINISH:
ESP_LOGI(TAG, "HTTP_EVENT_ON_FINISH:%d, %d K", file_total_len, file_total_len / 1024);
audio_player_play(record_audio_buffer, file_total_len);
break;
// Handle when the HTTP client is disconnected
case HTTP_EVENT_DISCONNECTED:
ESP_LOGI(TAG, "HTTP_EVENT_DISCONNECTED");
break;
// Handle when a redirection occurs in the HTTP request
case HTTP_EVENT_REDIRECT:
ESP_LOGI(TAG, "HTTP_EVENT_REDIRECT");
break;
}
return ESP_OK;
}
“HTTP_EVENT_ON_DATA” event is used to handle the audio data received from the server. The audio data is stored in a buffer called “*record_audio_buffer” *and the total length of the audio data received is stored in a variable called “file_total_len”. If the total length of the audio data received is less than a predefined “MAX_FILE_SIZE”, the data is copied into the “record_audio_buffer”.
Finally, the “*HTTP_EVENT_ON_FINISH *”event is used to handle the end of the HTTP response. In this case, the “*record_audio_buffer” *is passed to a function called “audio_player_play”which plays the audio.
Display#
For display we uses LVGL, an open-source embedded graphics library that is gaining popularity for its powerful and visually appealing features and low memory footprints. LVGL has also released a visual drag-and-drop UI editor called SquareLine Studio. It’s a powerful tool that makes it easy to create beautiful GUIs for your applications.To integrate LVGL with your project, Espressif Systems provides an official package manager tool. This tool allows you to directly add LVGL and related porting components to your project, saving you time and effort. For more information follow the official blogs and documentations.
Conclusion#
The integration of OpenAI’s ChatGPT with Espressif’s ESP-BOX has opened up new possibilities for creating powerful and intelligent IoT devices. The ESP-BOX provides a flexible and customizable AIoT development platform with features like far-field voice interaction, offline speech commands recognition, and a reusable GUI framework. By combining these capabilities with the OpenAI API, developers can create voice-controlled chatbots and enhance user experiences in IoT applications.

Don’t forget to check out Espressif Systems’ GitHub repository for more open-source demos on ESP-IoT-Solution, ESP-SR, and ESP-BOX. The source code for this project will be found here . As part of our future plans, we aim to introduce a component for the OpenAI API that will offer a user-friendly functions.
